
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
// MSSQLQueryBuilderSpec.cfc
function orWhere() {
// If just a string is returned, we assume the bindings is an empty array ([])
return {
sql = "SELECT * FROM [users] WHERE [id] = ? OR [email] = ?",
bindings = [ 1, "foo" ]
};
}// OracleSchemaBuilderSpec.cfc
function boolean() {
// returns an array since schema builder can execute multiple statements.
return [ "CREATE TABLE ""USERS"" (""ACTIVE"" NUMBER(1, 0) NOT NULL)" ];
}referencesonTableschema.create( "users", function( table ) {
table.string( "first_name" );
table.string( "last_name" );
table.index( [ "first_name", "last_name" ], "idx_users_full_name" );
} );CREATE TABLE `users` (
`first_name` VARCHAR(255) NOT NULL,
`last_name` VARCHAR(255) NOT NULL,
INDEX `idx_users_full_name` (`first_name`, `last_name`)
)schema.create( "users", function( table ) {
table.unsignedInteger( "country_id" );
table.foreignKey( "country_id" ).references( "id" ).onTable( "countries" );
} );CREATE TABLE `users` (
`country_id` INTEGER UNSIGNED NOT NULL,
CONSTRAINT `fk_users_country_id` FOREIGN KEY (`country_id`) REFERENCES `countries` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION
)schema.create( "posts_users", function( table ) {
table.unsignedInteger( "post_id" ).references( "id" ).onTable( "posts" );
table.unsignedInteger( "user_id" ).references( "id" ).onTable( "users" );
table.primaryKey( [ "post_id", "user_id" ], "pk_posts_users" );
} );CREATE TABLE `posts_users` (
`post_id` VARCHAR(255) NOT NULL,
`user_id` VARCHAR(255) NOT NULL,
INDEX `idx_users_full_name` (`first_name`, `last_name`),
CONSTRAINT `fk_posts_users_post_id` FOREIGN KEY (`post_id`) REFERENCES `posts` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT `fk_posts_users_user_id` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT ""pk_users_first_name_last_name"" PRIMARY KEY (""first_name"", ""last_name"")
)schema.create( "users", function( table ) {
table.increments( "id" );
table.string( "username ");
table.unique( "username" );
} );CREATE TABLE `users` (
`id` INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,
UNIQUE (`username`)
)query.from( "users" ).get();SELECT * FROM `users`query.from( "users" ).get( [ "id", "name" ] );SELECT `id`, `name` FROM `users`query.from( "users" ).first();SELECT * FROM `users`
LIMIT(1)query.from( "users" ).firstOrFail();SELECT * FROM `users`
LIMIT(1)query.from( "users" ).values( "firstName" );[ "jon", "jane", "jill", ... ]qb.from( "users" ).values( qb.raw( "CONCAT(fname, ' ', lname) AS fullName" ) );query.from( "users" ).valuesRaw( "CONCAT(fname, ' ', lname) AS fullName" );query.from( "users" ).value( "firstName" );"jon"qb.from( "users" ).value( qb.raw( "CONCAT(fname, ' ', lname) AS fullName" ) );query.from( "users" ).valueRaw( "CONCAT(fname, ' ', lname) AS fullName" );query.from( "users" ).chunk( 100, function( users ) {
// Process the users here
// Returning false from the callback stops processing
} );query.from( "users" )
.paginate();{
"pagination": {
"maxRows": 25,
"offset": 0,
"page": 1,
"totalPages": 2,
"totalRecords": 45
},
"results": [ { /* ... */ }, ]
}query.from( "users" )
.simplePaginate();{
"pagination": {
"maxRows": 25,
"offset": 0,
"page": 1,
"hasMore": true
},
"results": [ { /* ... */ }, ]
}query.from( "users" )
.groupBy( "country" );SELECT *
FROM `users`
GROUP BY `country`query.from( "users" )
.groupBy( "country,city" );SELECT *
FROM `users`
GROUP BY `country`, `city`query.from( "users" )
.groupBy( [ "country", "city" ] );SELECT *
FROM `users`
GROUP BY `country`, `city`query.from( "users" )
.groupBy( "country" )
.groupBy( "city" );SELECT *
FROM `users`
GROUP BY `country`, `city`query.from( "users" )
.groupBy( query.raw( "DATE(created_at)" ) );SELECT *
FROM `users`
GROUP BY DATE(created_at)query.from( "users" )
.groupBy( "email" )
.having( "email", ">", 1 );SELECT *
FROM `users`
GROUP BY `email`
HAVING `email` > ?query.from( "users" )
.groupBy( "email" )
.having( query.raw( "COUNT(email)" ), ">", 1 );SELECT *
FROM `users`
GROUP BY `email`
HAVING COUNT(email) > ?[
{
"sql": "CREATE TABLE `users` (`id` INT PRIMARY KEY AUTO_INCREMENT, `email` VARCHAR NOT NULL)",
"bindings": [],
"options": { "datasource": "main" },
"returnObject": "array",
"pretend": false,
"result": {},
"executionTime": 21
}
]{
"result": "Value of the `result` parameter to `queryExecute`",
"query": "Return value of running `queryExecute` - a CFML query object"
}query.from( "users" )
.insert( {
"name" = "Robert",
"email" = "[email protected]",
"age" = 55
} );INSERT INTO `users` (`age`, `email`, `name`)
VALUES (?, ?, ?)query.from( "users" )
.insert( {
"name" = "Robert",
"email" = "[email protected]",
"age" = { value = 55, cfsqltype = "CF_SQL_INTEGER" }
} );INSERT INTO `users` (`age`, `email`, `name`)
VALUES (?, ?, ?)query.from( "users" )
.insert( {
"name" = "Robert",
"email" = "[email protected]",
"updatedDate" = query.raw( "NOW()" )
} );INSERT INTO `users` (`age`, `email`, `updatedDate`)
VALUES (?, ?, NOW())query.from( "users" ).insert( [
{ "email" = "[email protected]", "name" = "John Doe" },
{ "email" = "[email protected]", "name" = "Jane Doe" }
] );INSERT INTO `users` (`email`, `name`)
VALUES (?, ?), (?, ?)INSERT ALL
INTO "USERS" ("EMAIL", "NAME") VALUES (?, ?)
INTO "USERS" ("EMAIL", "NAME") VALUES (?, ?)
SELECT 1 FROM dualquery.from( "users" )
.insertIgnore(
values = [
{ "email" = "foo", "name" = "bar" },
{ "email" = "baz", "name" = "bam" }
],
target = [ "email" ]
);INSERT IGNORE INTO `users` (`email`, `name`)
VALUES (?, ?), (?, ?)MERGE [users] AS [qb_target]
USING (VALUES (?, ?), (?, ?)) AS [qb_src] ([email], [name])
ON [qb_target].[email] = [qb_src].[email]
WHEN NOT MATCHED BY TARGET THEN
INSERT ([email], [name]) VALUES ([email], [name]);INSERT INTO "users" ("email", "name")
VALUES (?, ?), (?, ?)
ON CONFLICT DO NOTHINGMERGE INTO "USERS" "QB_TARGET"
USING (SELECT ?, ? FROM dual UNION ALL SELECT ?, ? FROM dual) "QB_SRC"
ON "QB_TARGET"."EMAIL" = "QB_SRC"."EMAIL"
WHEN NOT MATCHED THEN
INSERT ("EMAIL", "NAME")
VALUES ("QB_SRC"."EMAIL", "QB_SRC"."NAME")qb.from( "users" )
.insertUsing( function( q ) {
q.from( "activeDirectoryUsers" )
.select( [ "email", "modifiedDate AS createdDate" ] )
.where( "active", 1 );
} );INSERT INTO `users` (`email`, `createdDate`)
SELECT `email`, `modifiedDate` AS `createdDate`
FROM `activeDirectoryUsers`
WHERE `active` = ?qb.from( "users" )
.insertUsing(
columns = [ "email", "createdDate" ],
source = function( q ) {
q.from( "activeDirectoryUsers" )
.select( [ "email", "modifiedDate" ] )
.where( "active", 1 );
}
);INSERT INTO `users` (`email`, `createdDate`)
SELECT `email`, `modifiedDate`
FROM `activeDirectoryUsers`
WHERE `active` = ?qb.from( "users" )
.insertUsing(
qb.newQuery()
.from( "activeDirectoryUsers" )
.select( [ "email", "modifiedDate AS createdDate" ] )
.where( "active", 1 )
);INSERT INTO `users` (`email`, `createdDate`)
SELECT `email`, `modifiedDate` AS `createdDate`
FROM `activeDirectoryUsers`
WHERE `active` = ?query.from( "users" )
.update( {
"email" = "foo",
"name" = "bar"
} );UPDATE `users`
SET `email` = ?,
`name` = ?query.from( "users" )
.update( {
"email" = "foo",
"name" = "bar",
"updatedDate" = { value = now(), cfsqltype = "CF_SQL_TIMESTAMP" }
} );UPDATE `users`
SET `email` = ?,
`name` = ?,
`updatedDate` = ?query.from( "users" )
.whereId( 1 )
.update( {
"email" = "foo",
"name" = "bar"
} );UPDATE `users`
SET `email` = ?,
`name` = ?
WHERE `Id` = ?query.from( "hits" )
.where( "page", "someUrl" )
.update( {
"count" = query.raw( "count + 1" )
} );UPDATE `hits`
SET `count` = count + 1
WHERE `page` = ?query.from("user")
.whereId( 10 )
.update( {
manager_FK = { value = "", null=true },
} )query.from("user")
.whereId( 10 )
.update( {
manager_FK = { value = null },
} )qb.table( "employees" )
.update( {
"departmentName" = function( q ) {
q.from( "departments" )
.select( "name" )
.whereColumn( "employees.departmentId", "departments.id" );
} )
} );UPDATE `employees`
SET `departmentName` = (
SELECT `name`
FROM `departments`
WHERE `employees`.`departmentId` = `departments`.`id`
)qb.table( "employees" )
.update( {
"departmentName" = qb.newQuery()
.from( "departments" )
.select( "name" )
.whereColumn( "employees.departmentId", "departments.id" )
} )
} );qb.table( "employees" )
.join( "departments", "departments.id", "employees.departmentId" )
.update( {
"employees.departmentName": qb.raw( "departments.name" )
} );UPDATE `employees`
INNER JOIN `departments`
ON `departments`.`id` = `employees`.`departmentId`
SET `employees`.`departmentName` = departments.nameUPDATE [employees]
SET [employees].[departmentName] = departments.name
FROM [employees]
INNER JOIN [departments]
ON [departments].[id] = [employees].[departmentId]UPDATE "employees"
SET "employees"."departmentName" = departments.name
FROM "departments"
WHERE "departments"."id" = "employees"."departmentId"query.from( "users" )
.whereId( 1 )
.addUpdate( {
"email" = "foo",
"name" = "bar"
} )
.when( true, function( q ) {
q.addUpdate( {
"foo": "yes"
} );
} )
.when( false, function( q ) {
q.addUpdate( {
"bar": "no"
} );
} )
.update();UPDATE `users`
SET `email` = ?,
`foo` = ?,
`name` = ?
WHERE `Id` = ?query.from( "users" )
.where( "email", "foo" )
.updateOrInsert( {
"email" = "foo",
"name" = "baz"
} );UPDATE `users`
SET `email` = ?,
`name` = ?
WHERE `email` = ?
LIMIT 1query.from( "users" )
.where( "email", "foo" )
.updateOrInsert( {
"email" = "foo",
"name" = "baz"
} );INSERT INTO `users` (`email`, `name`)
VALUES (?, ?)qb.table( "users" )
.upsert(
values = [
{
"username": "johndoe",
"active": 1,
"createdDate": "2021-09-08 12:00:00",
"modifiedDate": "2021-09-08 12:00:00"
},
{
"username": "janedoe",
"active": 1,
"createdDate": "2021-09-10 10:42:13",
"modifiedDate": "2021-09-10 10:42:13"
},
],
target = [ "username" ],
update = [ "active", "modifiedDate" ],
);INSERT INTO `users`
(`active`, `createdDate`, `modifiedDate`, `username`)
VALUES
(?, ?, ?, ?),
(?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
`active` = VALUES(`active`),
`modifiedDate` = VALUES(`modifiedDate`)MERGE [users] AS [qb_target]
USING (VALUES (?, ?, ?, ?), (?, ?, ?, ?)) AS [qb_src]
([active], [createdDate], [modifiedDate], [username])
ON [qb_target].[username] = [qb_src].[username]
WHEN MATCHED THEN UPDATE
SET [active] = [qb_src].[active],
[modifiedDate] = [qb_src].[modifiedDate]
WHEN NOT MATCHED BY TARGET THEN INSERT
([active], [createdDate], [modifiedDate], [username])
VALUES
([active], [createdDate], [modifiedDate], [username])INSERT INTO "users"
("active", "createdDate", "modifiedDate", "username")
VALUES
(?, ?, ?, ?),
(? ,? ,? ,?)
ON CONFLICT ("username") DO UPDATE
"active" = EXCLUDED."active",
"modifiedDate" = EXCLUDED."modifiedDate"MERGE INTO "USERS" "QB_TARGET"
USING (
SELECT ?, ?, ?, ? FROM dual
UNION ALL
SELECT ?, ?, ?, ? FROM dual
) "QB_SRC"
ON "QB_TARGET"."USERNAME" = "QB_SRC"."USERNAME"
WHEN MATCHED THEN UPDATE
SET "ACTIVE" = "QB_SRC"."ACTIVE",
"MODIFIEDDATE" = "QB_SRC"."MODIFIEDDATE"
WHEN NOT MATCHED THEN INSERT
("ACTIVE", "CREATEDDATE", "MODIFIEDDATE", "USERNAME")
VALUES
("QB_SRC"."ACTIVE", "QB_SRC"."CREATEDDATE", "QB_SRC"."MODIFIEDDATE", "QB_SRC"."USERNAME")qb.table( "stats" )
.upsert(
values = [
{ "postId": 1, "viewedDate": "2021-09-08", "views": 1 },
{ "postId": 2, "viewedDate": "2021-09-08", "views": 1 }
],
target = [ "postId", "viewedDate" ],
update = { "views": qb.raw( "stats.views + 1" ) }
);INSERT INTO `stats`
(`postId`, `viewedDate`, `views`)
VALUES
(?, ?, ?),
(?, ?, ?)
ON DUPLICATE KEY UPDATE
`views` = stats.views + 1MERGE [stats] AS [qb_target]
USING (VALUES (?, ?, ?), (?, ?, ?)) AS [qb_src]
([postId], [viewedDate], [views])
ON [qb_target].[postId] = [qb_src].[postId]
AND [qb_target].[viewedDate] = [qb_src].[viewedDate]
WHEN MATCHED THEN UPDATE
SET [views] = stats.views + 1
WHEN NOT MATCHED BY TARGET THEN INSERT
([postId], [viewedDate], [views])
VALUES
([postId], [viewedDate], [views])INSERT INTO "stats"
("postId", "viewedDate", "views")
VALUES
(?, ?, ?),
(?, ?, ?)
ON CONFLICT ("postId", "viewedDate") DO UPDATE
"views" = stats.views + 1MERGE INTO "STATS" "QB_TARGET"
USING (
SELECT ?, ?, ? FROM dual
UNION ALL
SELECT ?, ?, ? FROM dual
) "QB_SRC"
ON "QB_TARGET"."POSTID" = "QB_SRC"."POSTID"
AND "QB_TARGET"."VIEWEDDATE" = "QB_SRC"."VIEWEDDATE"
WHEN MATCHED THEN UPDATE
SET "VIEWS" = stats.views + 1
WHEN NOT MATCHED THEN INSERT
("POSTID", "VIEWEDDATE", "VIEWS")
VALUES
("QB_SRC"."POSTID", "QB_SRC"."VIEWEDDATE", "QB_SRC"."VIEWS")qb.table( "stats" )
.upsert(
source = function( q ) {
q.from( "activeDirectoryUsers" )
.select( [
"username",
"active",
"createdDate",
"modifiedDate"
] );
},
values = [ "username", "active", "createdDate", "modifiedDate" ],
target = [ "username" ],
update = [ "active", "modifiedDate" ]
);INSERT INTO `users`
(`username`, `active`, `createdDate`, `modifiedDate`)
SELECT `username`, `active`, `createdDate`, `modifiedDate`
FROM `activeDirectoryUsers`
ON DUPLICATE KEY UPDATE
`active` = VALUES(`active`),
`modifiedDate` = VALUES(`modifiedDate`)MERGE [users] AS [qb_target]
USING (
SELECT [username], [active], [createdDate], [modifiedDate]
FROM [activeDirectoryUsers]
) AS [qb_src]
ON [qb_target].[username] = [qb_src].[username]
WHEN MATCHED THEN UPDATE
SET [active] = [qb_src].[active],
[modifiedDate] = [qb_src].[modifiedDate]
WHEN NOT MATCHED BY TARGET THEN INSERT
([username], [active], [createdDate], [modifiedDate])
VALUES ([username], [active], [createdDate], [modifiedDate]);INSERT INTO "users"
("username", "active", "createdDate", "modifiedDate")
SELECT "username", "active", "createdDate", "modifiedDate"
FROM "activeDirectoryUsers"
ON CONFLICT ("username") DO UPDATE
"active" = EXCLUDED."active",
"modifiedDate" = EXCLUDED."modifiedDate"MERGE INTO "USERS" "QB_TARGET"
USING (
SELECT "USERNAME", "ACTIVE", "CREATEDADATE", "MODIFIEDDATE"
FROM "ACTIVEDIRECTORYUSERS"
) "QB_SRC"
ON "QB_TARGET"."USERNAME" = "QB_SRC"."USERNAME"
WHEN MATCHED THEN UPDATE
SET "ACTIVE" = "QB_SRC"."ACTIVE",
"MODIFIEDDATE" = "QB_SRC"."MODIFIEDDATE"
WHEN NOT MATCHED THEN INSERT
("USERNAME", "ACTIVE", "CREATEDDATE", "MODIFIEDDATE")
VALUES
(
"QB_SRC"."USERNAME",
"QB_SRC"."ACTIVE",
"QB_SRC"."CREATEDDATE",
"QB_SRC"."MODIFIEDDATE"
)query.from( "users" )
.where( "email", "foo" )
.delete();DELETE FROM `users`
WHERE `email` = ?query.from( "users" )
.delete( 1 );DELETE FROM `users`
WHERE `id` = ?query.from( "users" )
.returning( "id" )
.insert( {
"email" = "foo",
"name" = "bar"
} );INSERT INTO [users] ([email], [name])
OUTPUT INSERTED.[id]
VALUES (?, ?)INSERT INTO "users" ("email", "name")
VALUES (?, ?)
RETURNING "id"INSERT INTO "users" ("email", "name")
VALUES (?, ?)
RETURNING "id"query.table( "users" )
.returning( [ "id", "modifiedDate" ] )
.where( "id", 1 )
.update( { "email": "[email protected]" } );UPDATE [users]
SET [email] = ?
OUTPUT INSERTED.[id], INSERTED.[modifiedDate]
WHERE [id] = ?UPDATE "users"
SET "email" = ?
WHERE "id" = ?
RETURNING "id", "modifiedDate"UPDATE "users"
SET "email" = ?
WHERE "id" = ?
RETURNING "id", "modifiedDate"query.table( "users" )
.returning( "id" )
.where( "active", 0 )
.delete();DELETE FROM [users]
OUTPUT DELETED.[id]
WHERE [active] = ?DELETE FROM "users" WHERE "active" = ?
RETURNING "id"DELETE FROM "users" WHERE "active" = ?
RETURNING "id"qb.from( "users" )
.where( "id", 1 )
.returningRaw( [
"DELETED.modifiedDate AS oldModifiedDate",
"INSERTED.modifiedDate AS newModifiedDate"
] )
.update( { "email": "[email protected]" } );UPDATE [users]
SET [email] = ?
OUTPUT
DELETED.modifiedDate AS oldModifiedDate,
INSERTED.modifiedDate AS newModifiedDate
WHERE [id] = ?moduleSettings = {
"qb": {
"returnFormat": "array"
}
};moduleSettings = {
qb = {
defaultGrammar = "MySQLGrammar@qb"
}
};var grammar = new qb.models.Grammars.MySQLGrammar();
var builder = new qb.models.Query.QueryBuilder( grammar );moduleSettings = {
qb : {
"defaultGrammar": "AutoDiscover@qb",
"defaultReturnFormat": "array",
"preventDuplicateJoins": false,
"strictDateDetection": true,
"numericSQLType": "CF_SQL_NUMERIC",
"integerSQLType": "CF_SQL_INTEGER",
"decimalSQLType": "CF_SQL_DECIMAL",
"autoAddScale": true,
"autoDeriveNumericType": true,
"defaultOptions": {},
"sqlCommenter": {
"enabled": false,
"commenters": [
{ "class": "FrameworkCommenter@qb", "properties": {} },
{ "class": "RouteInfoCommenter@qb", "properties": {} },
{ "class": "DBInfoCommenter@qb", "properties": {} }
]
},
"shouldMaxRowsOverrideToAll": function( maxRows ) {
return maxRows <= 0;
}
}
}moduleSettings = {
qb = {
defaultGrammar = "MySQLGrammar@qb",
numericSQLType = "CF_SQL_BIGINT"
}
};this.mappings = {
"/qb" = expandPath("./subsystems/qb")
};qb = {
diLocations = "/qb/models",
diConfig = {
loadListener = function( di1 ) {
di1.declare( "BaseGrammar" ).instanceOf( "qb.models.Query.Grammars.Grammar" ).done()
.declare( "MySQLGrammar" ).instanceOf( "qb.models.Query.Grammars.MySQLGrammar" ).done()
.declare( "QueryUtils" ).instanceOf( "qb.models.Query.QueryUtils" ).done()
.declare( "QueryBuilder" ).instanceOf( "qb.models.Query.QueryBuilder" )
.withOverrides({
grammar = di1.getBean( "MySQLGrammar" ),
utils = di1.getBean( "QueryUtils" ),
returnFormat = "array"
})
.asTransient();
}
}
}// Create an instance of qb
builder = getBeanFactory( "qb" ).getBean( "QueryBuilder" );
// Query the database
posts = builder.from( "Posts" ).get();
posts = builder.from( "Posts" ).where( "IsDraft", "=", 0 ).get();moduleSettings = {
"qb": {
"returnFormat": "query"
}
};var qb = wirebox.getInstance( "QueryBuilder@qb" );
qb
.setReturnFormat( 'query' )
.from( 'users' )
.get()moduleSettings = {
"qb": {
"returnFormat": function( q ) {
return application.wirebox.getInstance(
"name" = "Collection",
"initArguments" = { "collection": q }
);
}
}
};query.setColumnFormatter( function( column ) {
return lcase( arguments.column );
} );// This will cause you pain and grief...
var user = query.from( "users" )
.where( "username", rc.username )
.first();
var posts = query.from( "posts" ).get();
// This will error because `username` is not a column in `posts`.component {
property name="query" inject="QueryBuilder@qb";
function create( event, rc, prc ) {
// This will cause you pain and grief...
query.table( "posts" )
.where( "id", rc.id )
.update( event.getOnly( [ "body" ] ) );
}
}component {
function create( event, rc, prc ) {
getInstance( "QueryBuilder@qb" )
.table( "posts" )
.where( "id", rc.id )
.update( event.getOnly( [ "body" ] ) );
}
}component {
property name="query" inject="provider:QueryBuilder@qb";
function create( event, rc, prc ) {
query.table( "posts" )
.where( "id", rc.id )
.update( event.getOnly( [ "body" ] ) );
}
}// This will cause you pain and grief...
var user = query.from( "users" )
.where( "username", rc.username )
.first();
var posts = query.newQuery().from( "posts" ).get();
// This will work as we expect it to.var q1 = query.from( "users" ).where( "firstName", "like", "Jo%" );
var q2 = q1.reset();
q2.getColumns(); // "*"schema.create( "users", function( table ) {
table.increments( "id" );
table.string( "email" );
table.string( "password" );
table.timestamp( "created_date" );
table.timestamp( "modified_date" );
table.timestamp( "last_logged_in" ).nullable();
} );CREATE TABLE `users` (
`id` INTEGER(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`email` VARCHAR(255) NOT NULL,
`password` VARCHAR(255) NOT NULL,
`created_date` TIMESTAMP NOT NULL,
`modified_date` TIMESTAMP NOT NULL,
`last_logged_in` TIMESTAMP,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)query.from( "users" ).select( query.raw( "MAX(created_date)" ) );
SELECT MAX(created_date) FROM `users`
moduleSettings = {
"qb": {
"sqlCommenter": {
"enabled": true
}
}
};SELECT * FROM foo /*action='index',dbDriver='mysql-connector-java-8.0.25%20%28Revision%3A%2008be9e9b4cba6aa115f9b27b215887af40b159e0%29',event='Main.index',framework='coldbox-6.0.0',handler='Main',route='%2F'*/settings = {
"sqlCommenter": {
"enabled": false,
"commenters": [
{ "class": "FrameworkCommenter@qb", "properties": {} },
{ "class": "RouteInfoCommenter@qb", "properties": {} },
{ "class": "DBInfoCommenter@qb", "properties": {} }
]
}
};component singleton accessors="true" {
property name="coldboxVersion" inject="coldbox:coldboxSetting:version";
property name="properties";
/**
* Returns a struct of key/value comment pairs to append to the SQL.
*
* @sql The SQL to append the comments to. This is provided if you need to
* inspect the SQL to make any decisions about what comments to return.
* @datasource The datasource that will execute the query. If null, the default datasource will be used.
* This can be used to make decisions about what comments to return.
*/
public struct function getComments( required string sql, string datasource ) {
return { "version": "coldbox-#variables.coldboxVersion#" };
}
}component singleton accessors="true" {
property name="auth" inject="AuthenticationService@cbauth";
property name="properties";
/**
* Returns a struct of key/value comment pairs to append to the SQL.
*
* @sql The SQL to append the comments to. This is provided if you need to
* inspect the SQL to make any decisions about what comments to return.
* @datasource The datasource that will execute the query. If null, the default datasource will be used.
* This can be used to make decisions about what comments to return.
*/
public struct function getComments( required string sql, string datasource ) {
return { "userId": variables.auth.getUserId() };
}
}getInstance( "ColdBoxSQLCommenter@qb" )
.parseCommentedSQL( "SELECT * FROM foo /*action='index',dbDriver='mysql-connector-java-8.0.25%20%28Revision%3A%2008be9e9b4cba6aa115f9b27b215887af40b159e0%29',event='Main.index',framework='coldbox-6.0.0',handler='Main',route='%2F'*/" );{
"sql": "SELECT * FROM foo",
"comments": {
"action": "index",
"dbDriver": "mysql-connector-java-8.0.25 (Revision: 08be9e9b4cba6aa115f9b27b215887af40b159e0)",
"event": "Main.index",
"framework": "coldbox-6.0.0",
"handler": "Main",
"route": "/"
}
}getInstance( "ColdBoxSQLCommenter@qb" )
.parseCommentString(
"/*action='index',dbDriver='mysql-connector-java-8.0.25%20%28Revision%3A%2008be9e9b4cba6aa115f9b27b215887af40b159e0%29',event='Main.index',framework='coldbox-6.0.0',handler='Main',route='%2F'*/"
);{
"action": "index",
"dbDriver": "mysql-connector-java-8.0.25 (Revision: 08be9e9b4cba6aa115f9b27b215887af40b159e0)",
"event": "Main.index",
"framework": "coldbox-6.0.0",
"handler": "Main",
"route": "/"
}schema.drop( "user_logins" );DROP TABLE `user_logins`schema.dropIfExists( "user_logins" );DROP TABLE IF EXISTS `user_logins`query.from( "posts" )
.when( someFlag, function( q ) {
q.orderBy( "published_date", "desc" );
} )
.get();query.from( "posts" )
.when(
someFlag,
function( q ) {
q.orderBy( "published_date", "desc" );
},
function( q ) {
q.orderBy( "modified_date", "desc" );
}
);qb.from( "users" )
.where( "active", 1 )
.when( len( url.q ), function( q ) {
q.where( "username", "LIKE", q & "%" )
.orWhere( "email", "LIKE", q & "%" );
} );SELECT *
FROM "users"
WHERE "active" = ?
AND (
"username" = ?
OR "email" = ?
)// qb
query.with( "UserCTE", function ( q ) {
q
.select( [ "fName as firstName", "lName as lastName" ] )
.from( "users" )
.where( "disabled", 0 );
} )
.from( "UserCTE" )
.get();WITH `UserCTE` AS (
SELECT
`fName` as `firstName`,
`lName` as `lastName`
FROM `users`
WHERE `disabled` = 0
) SELECT * FROM `UserCTE`// qb
var cte = query
.select( [ "fName as firstName", "lName as lastName" ] )
.from( "users" )
.where( "disabled", 0 );
query.with( "UserCTE", cte )
.from( "UserCTE" )
.get();WITH `UserCTE` AS (
SELECT
`fName` as `firstName`,
`lName` as `lastName`
FROM `users`
WHERE `disabled` = 0
)
SELECT * FROM `UserCTE`query.with( "UserCTE", function ( q ) {
q.select( [ "id", "fName as firstName", "lName as lastName" ] )
.from( "users" )
.where( "disabled", 0 );
} )
.with( "BlogCTE", function ( q ) {
q.from( "blogs" )
.where( "disabled", 0 );
} )
.from( "BlogCTE as b" )
.join( "UserCTE as u", "b.Creator", "u.id" )
.get();WITH `UserCTE` AS (
SELECT
`id`,
`fName` as `firstName`,
`lName` as `lastName`
FROM `users`
WHERE `disabled` = 0
),
`BlogCTE` AS (
SELECT *
FROM `blogs`
WHERE `disabled` = 0
)
SELECT *
FROM `BlogCTE` AS `b`
INNER JOIN `UserCTE` AS `u`
ON `b`.`Creator` = `u`.`id`query
.withRecursive( "Hierarchy", function ( q ) {
q.select( [ "Id", "ParentId", "Name", q.raw( "0 AS [Generation]" ) ] )
.from( "Sample" )
.whereNull( "ParentId" )
// use recursion to join the child rows to their parents
.unionAll( function ( q ) {
q.select( [
"child.Id",
"child.ParentId",
"child.Name",
q.raw( "[parent].[Generation] + 1" )
] )
.from( "Sample as child" )
.join( "Hierarchy as parent", "child.ParentId", "parent.Id" );
} );
}, [ "Id", "ParentId", "Name", "Generation" ] )
.from( "Hierarchy" )
.get();WITH [Hierarchy] ([Id], [ParentId], [Name], [Generation]) AS (
SELECT
[Id],
[ParentId],
[Name],
0 AS [Generation]
FROM [Sample]
WHERE [ParentId] IS NULL
UNION ALL
SELECT
[child].[Id],
[child].[ParentId],
[child].[Name],
[parent].[Generation] + 1
FROM [Sample] AS [child]
INNER JOIN [Hierarchy] AS [parent]
ON [child].[ParentId] = [parent].[Id]
) SELECT * FROM [Hierarchy]moduleSettings = {
"qb": {
"defaultOptions": {
"timeout": 60
}
}
};component {
function afterAspectsLoad() {
binder.map( "MyCustomQueryBuilder" )
.to( "qb.models.Query.QueryBuilder" )
.initArg( name = "grammar", ref = "AutoDiscover@qb" )
.initArg( name = "defaultOptions", value = {
"datasource": "my_custom_datasource"
} );
}
}query.from( "users" )
.get( options = { datasource: "MyOtherDatasourceName" } );var query = wirebox.getInstance( "QueryBuilder@qb" )
.setGrammar( wirebox.getInstance( "SqlServerGrammar@qb" ) );selectfromorderByquery.from( "users" )
.select( "name" )
.where( "id", 1 )
.union( function ( q ) {
q.from( "users" )
.select( "name" )
.where( "id", 2 );
} );SELECT `name`
FROM `users`
WHERE `id` = ?
UNION
SELECT `name`
FROM `users`
WHERE `id` = ?query.from( "users" )
.select( "name" )
.where( "id", 1 )
.union( function ( q ) {
q.from( "users" )
.select( "name" )
.where( "id", 2 );
} )
.union( function ( q ) {
q.from( "users" )
.select("name")
.where( "id", 3 );
} );SELECT `name`
FROM `users`
WHERE `id` = ?
UNION
SELECT `name`
FROM `users`
WHERE `id` = ?
UNION
SELECT `name`
FROM `users`
WHERE `id` = ?var q1 = query.newQuery()
.from( "users" )
.select( "name" )
.where( "id", 2 );
var q2 = query.newQuery()
.from( "users" )
.select( "name" )
.where( "id", 3 );
query.from( "users" )
.select( "name" )
.where( "id", 1 )
.union( q1 )
.union( q2 );SELECT `name`
FROM `users`
WHERE `id` = ?
UNION
SELECT `name`
FROM `users`
WHERE `id` = ?
UNION
SELECT `name`
FROM `users`
WHERE `id` = ?query.from( "users" )
.select( "name" )
.where( "id", 1 )
.unionAll( function( q ) {
q.from( "users" )
.select( "name" )
.where( "id", 2 );
} );SELECT `name`
FROM `users`
WHERE `id` = ?
UNION ALL
SELECT `name`
FROM `users`
WHERE `id` = ?query.from( "users" )
.select( "name" )
.where( "id", 1 )
.unionAll( function( q ) {
q.from( "users" )
.select( "name" )
.where( "id", 2 );
} )
.unionAll( function( q ) {
q.from( "users" )
.select( "name" )
.where( "id", 3 );
} );SELECT `name`
FROM `users`
WHERE `id` = ?
UNION ALL
SELECT `name`
FROM `users`
WHERE `id` = ?
UNION ALL
SELECT `name`
FROM `users`
WHERE `id` = ?var q1 = query.newQuery()
.from( "users" )
.select( "name" )
.where( "id", 2 );
var q2 = query.newQuery()
.from( "users" )
.select( "name" )
.where( "id", 3 );
query.from( "users" )
.select( "name" )
.where( "id", 1 )
.unionAll( q1 )
.unionAll( q2 );SELECT `name`
FROM `users`
WHERE `id` = ?
UNION ALL
SELECT `name`
FROM `users`
WHERE `id` = ?
UNION ALL
SELECT `name`
FROM `users`
WHERE `id` = ?query.from( "users" )
.limit( 5 );SELECT *
FROM `users`
LIMIT 5query.from( "users" )
.take( 5 );SELECT *
FROM `users`
LIMIT 5query.from( "users" )
.offset( 25 );SELECT *
FROM `users`
OFFSET 25query.from( "users" )
.forPage( 3, 15 );SELECT *
FROM `users`
LIMIT 15
OFFSET 30query.from( "users" );SELECT * FROM `users`query.from( "users as u" );SELECT * FROM `users` AS `u`query.table( "users" ).insert( { "name" = "jon" } );INSERT INTO `users` (`name`) VALUES (?)query.fromRaw( "[users] u (nolock)" ).get();SELECT * FROM [users] u (nolock) query.fromRaw(
"dbo.generateDateTable(?, ?, ?) as dt",
[ "2017-01-01", "2017-12-31", "m" ]
).get();SELECT * FROM dbo.generateDateTable(?, ?, ?) as dtquery.select( [ "firstName", "lastName" ] )
.fromSub( "legalUsers", function ( q ) {
q.select( [ "lName as lastName", "fName as firstName" ] )
.from( "users" )
.where( "age", ">=", 21 )
;
} )
.orderBy( "lastName" )
.get()SELECT `firstName`, `lastName`
FROM (
SELECT `lName` as `lastName`, `fName` as `firstName`
FROM `users`
WHERE `age` >= 21
) AS `legalUsers`
ORDER BY `lastName`var legalUsersQuery = query
.select( [ "lName as lastName", "fName as firstName" ] )
.from( "users" )
.where( "age", ">=", 21 );
query.select( [ "firstName", "lastName" ] )
.fromSub( "legalUsers", legalUsersQuery )
.orderBy( "lastName" )
.get();SELECT `firstName`, `lastName`
FROM (
SELECT `lName` as `lastName`, `fName` as `firstName`
FROM `users`
WHERE `age` >= 21
) AS `legalUsers`
ORDER BY `lastName`query.from( "users" )
.where
SELECT *
FROM `users`
WHERE
SELECT *
FROM [users] WITH (ROWLOCK,HOLDLOCK)
SELECT *
FROM "users"
WHERE
LOCK TABLE "USERS"
IN SHARE MODE NOWAIT;
country_iduuid split into and callback to queryquery.from( "users" )
.where( "id", 1 )
.lockForUpdate();SELECT *
FROM `users`
WHERE `id` = ?
FOR UPDATESELECT *
FROM [users] WITH (ROWLOCK,UPDLOCK,HOLDLOCK)
WHERE [id] = ?SELECT *
FROM "users"
WHERE "id" = ?
FOR UPDATESELECT *
FROM "USERS"
WHERE "ID" = ?
FOR UPDATEquery.from( "users" )
.where( "id", 1 )
.lockForUpdate( skipLocked = true )
.orderBy( "id" )
.limit( 5 );SELECT *
FROM `users`
WHERE `id` = ?
ORDER BY `id`
LIMIT 5
FOR UPDATE SKIP LOCKEDSELECT TOP 5 *
FROM [users] WITH (ROWLOCK,UPDLOCK,HOLDLOCK,READPAST)
WHERE [id] = ?
ORDER BY [id]SELECT *
FROM "users"
WHERE "id" = ?
ORDER BY "id"
LIMIT 1
FOR UPDATE SKIP LOCKEDquery.from( "users" )
.where( "id", 1 )
.noLock();SELECT *
FROM [users] WITH (NOLOCK)
WHERE [id] = ?schema.create( "users", function( table ) {
table.unsignedInteger( "country_id" ).references( "id" ).onTable( "countries" );
} );CREATE TABLE `users` (
`country_id` INTEGER UNSIGNED NOT NULL,
CONSTRAINT `fk_users_country_id` FOREIGN KEY (`country_id`) REFERENCES `countries` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION
)schema.create( "users", function( table ) {
table.unsignedInteger( "country_id" ).references( "id" ).onTable( "countries" );
} );CREATE TABLE `users` (
`country_id` INTEGER UNSIGNED NOT NULL,
CONSTRAINT `fk_users_country_id` FOREIGN KEY (`country_id`) REFERENCES `countries` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION
)schema.create( "users", function( table ) {
table.unsignedInteger( "country_id" )
.references( "id" )
.onTable( "countries" )
.onUpdate( "CASCADE" );
} );CREATE TABLE `users` (
`country_id` INTEGER UNSIGNED NOT NULL,
CONSTRAINT `fk_users_country_id` FOREIGN KEY (`country_id`) REFERENCES `countries` (`id`) ON UPDATE CASCADE ON DELETE NO ACTION
)schema.create( "users", function( table ) {
table.unsignedInteger( "country_id" )
.references( "id" )
.onTable( "countries" )
.onDelete( "SET NULL" );
} );CREATE TABLE `users` (
`country_id` INTEGER UNSIGNED NOT NULL,
CONSTRAINT `fk_users_country_id` FOREIGN KEY (`country_id`) REFERENCES `countries` (`id`) ON UPDATE NO ACTION ON DELETE SET NULL
)moduleSettings = {
"qb": {
"shouldMaxRowsOverrideToAll": function( maxRows ) {
return false;
}
}
};moduleSettings = {
"qb": {
"autoDeriveNumericType": false
}
};moduleSettings = {
"qb": {
"strictDateDetection": false
}
};qb.from( "users" )
.where( "active", 1 )
.when( len( url.q ), function( q ) {
q.where( "username", "LIKE", q & "%" )
.orWhere( "email", "LIKE", q & "%" );
} );SELECT *
FROM "users"
WHERE "active" = ?
AND "username" = ?
OR "email" = ?qb.from( "users" )
.where( "active", 1 )
.where( function( q ) {
q.where( "username", "LIKE", q & "%" )
.orWhere( "email", "LIKE", q & "%" );
} );SELECT *
FROM "users"
WHERE "active" = ?
AND (
"username" = ?
OR "email" = ?
)// qb 8.0.0
qb.from( "users" )
.where( "active", 1 )
.when( len( url.q ), function( q ) {
q.where( "username", "LIKE", q & "%" )
.orWhere( "email", "LIKE", q & "%" );
} );SELECT *
FROM "users"
WHERE "active" = ?
AND (
"username" = ?
OR "email" = ?
)// qb 8.0.0
qb.from( "users" )
.where( "active", 1 )
.when( url.keyExists( "admin" ), function( q ) {
q.where( "admin", 1 )
.whereNotNull( "hireDate" );
} );SELECT *
FROM "users"
WHERE "active" = ?
AND "admin" = ?
AND "hireDate IS NOT NULLqb.from( "users" )
.where( "active", 1 )
.when( len( url.q ), function( q ) {
q.where( function( q2 ) {
q2.where( "username", "LIKE", q & "%" )
.orWhere( "email", "LIKE", q & "%" );
} );
} );SELECT *
FROM "users"
WHERE "active" = ?
AND (
"username" = ?
OR "email" = ?
)// qb 8.0.0
qb.from( "users" )
.where( "active", 1 )
.when(
condition = len( url.q ),
onTrue = function( q ) {
q.where( "username", "LIKE", q & "%" )
.orWhere( "email", "LIKE", q & "%" );
},
withoutScoping = true
);SELECT *
FROM "users"
WHERE "active" = ?
AND "username" = ?
OR "email" = ?qb.select( "name", "email", "createdDate" );qb.select( [ "name", "email", "createdDate" ] );moduleSettings = {
"qb": {
"defaultGrammar": "MSSQLGrammar@qb"
}
};public any function value(
required string column,
string defaultValue = "",
boolean throwWhenNotFound = false,
struct options = {}
);SELECT COUNT(*) AS aggregate FROM `usersSELECT COUNT(*) FROM [users]query.from( "users" ).where( "username", "like", "jon%" ).exists();SELECT COUNT(*) AS aggregate
FROM `users` WHERE `username` LIKE 'jon%'query.from( "users" ).count();query.from( "users" ).max( "age" );SELECT MAX(age) AS aggregate FROM `users`query.from( "users" ).min( "age" );SELECT MIN(age) AS aggregate FROM `users`query.from( "employees" ).sum( "salary" );SELECT SUM(salary) AS aggregate FROM `employees`query.from( "accounts" ).sumRaw( "netAdditions + netTransfers" )SELECT SUM(netAdditions + netTransfers) AS aggregate FROM `accounts`query.from( "users" ).columnList();[ "id", "firstName", "lastName", "username", "email", "password" ]var q = query.from( "users" )
.where( "active", "=", 1 );
writeOutput( q.toSQL() );SELECT * FROM "users" WHERE "active" = ?var q = query.from( "users" )
.where( "active", "=", 1 );
writeOutput( q.toSQL( showBindings = true ) );SELECT * FROM "users" WHERE "active" = {"value":1,"cfsqltype":"CF_SQL_NUMERIC","null":false}var q = query.from( "users" )
.where( "active", "=", 1 );
writeOutput( q.toSQL( showBindings = "inline" ) );SELECT * FROM "users" WHERE "active" = 1query.from( "users" )
.tap( function( q ) {
writeOutput( q.toSQL() & "<br>" );
} )
.where( "active", "=", 1 )
.tap( function( q ) {
writeOutput( q.toSQL() & "<br>" );
} );SELECT * FROM "users"
SELECT * FROM "users" WHERE "active" = ?query.from( "users" )
.dump()
.where( "active", "=", 1 )
.dump( label = "after where", showBindings = true, abort = true )
.get();SELECT * FROM "users"
SELECT * FROM "users" WHERE "active" = ?[
{
"sql": "SELECT * FROM `users` WHERE `active` = ?",
"bindings": [ { "value": 1, "sqltype": "bit" } ],
"options": { "datasource": "main" },
"returnObject": "array",
"pretend": false,
"result": {},
"executionTime": 21
}
]logbox = {
debug = [ "qb.models.Grammars" ]
};
// Plain old CFML
var results = queryExecute( "SELECT * FROM users" );
// qb
var qb = wirebox.getInstance( "QueryBuilder@qb" );
var results = qb.from( "users" ).get();// Plain old CFML
var results = queryExecute(
"SELECT * FROM posts WHERE published_at IS NOT NULL AND author_id IN ?",
[ { value = "5,10,27", cfsqltype = "CF_SQL_NUMERIC", list = true } ]
);
// qb
var qb = wirebox.getInstance( "QueryBuilder@qb" );
var results = qb.from( "posts" )
.whereNotNull( "published_at" )
.whereIn( "author_id", [ 5, 10, 27 ] )
.get();var qb = wirebox.getInstance( "QueryBuilder@qb" );
var results = qb.from( "posts" )
.orderBy( "published_at" )
.select( "post_id", "author_id", "title", "body" )
.whereLike( "author", "Ja%" )
.join( "authors", "authors.id", "=", "posts.author_id" )
.get();
// Becomes
var results = queryExecute(
"SELECT post_id, author_id, title, body FROM posts INNER JOIN authors ON authors.id = posts.author_id WHERE author LIKE ? ORDER BY published_at",
[ { value = "Ja%", cfsqltype = "CF_SQL_VARCHAR", list = false, null = false } ]
);moduleSettings = {
qb = {
defaultGrammar = "MySQLGrammar@qb"
}
};var grammar = new qb.models.Query.Grammars.MySQLGrammar();
var builder = new qb.models.Query.Builder( grammar );query.from( "users" )
.where( "id", "=", { value = 18, cfsqltype = "CF_SQL_VARCHAR" } );SELECT *
FROM `users`
WHERE `id` = ?query.table( "users" )
.insert( {
"id" = { value 1, cfsqltype = "CF_SQL_VARCHAR" },
"age" = 18,
"updatedDate" = { value = now(), cfsqltype = "CF_SQL_DATE" }
} );INSERT INTO `users`
(`id`, `age`, `updatedDate`)
VALUES
(?, ?, ?)moduleSettings = {
"qb": {
"strictDateDetection": true
}
};moduleSettings = {
"qb": {
"numericSQLType": "CF_SQL_INTEGER"
}
};moduleSettings = {
"qb": {
"autoDeriveNumericType": true,
"integerSqlType": "CF_SQL_INTEGER",
"decimalSqlType": "CF_SQL_DECIMAL"
}
};query.from( "users" )
.join( "logins", function( j ) {
j.on( "users.id", "logins.user_id" );
j.where( "logins.created_date", ">", dateAdd( "m", -1, "01 Jun 2019" ) );
} )
.where( "active", 1 );[
{ value = "01 May 2019", cfsqltype = "CF_SQL_TIMESTAMP" },
{ value = 1, cfsqltype = "CF_SQL_NUMERIC" }
]query.from( "users" )
.join( "logins", function( j ) {
j.on( "users.id", "logins.user_id" );
j.where( "logins.created_date", ">", dateAdd( "m", -1, "01 Jun 2019" ) );
} )
.where( "active", 1 );{
"commonTables" = [],
"select" = [],
"join" = [
{ value = "01 May 2019", cfsqltype = "CF_SQL_TIMESTAMP" },
],
"where" = [
{ value = 1, cfsqltype = "CF_SQL_NUMERIC" }
],
"union" = [],
"insert" = [],
"insertRaw" = [],
"update" = []
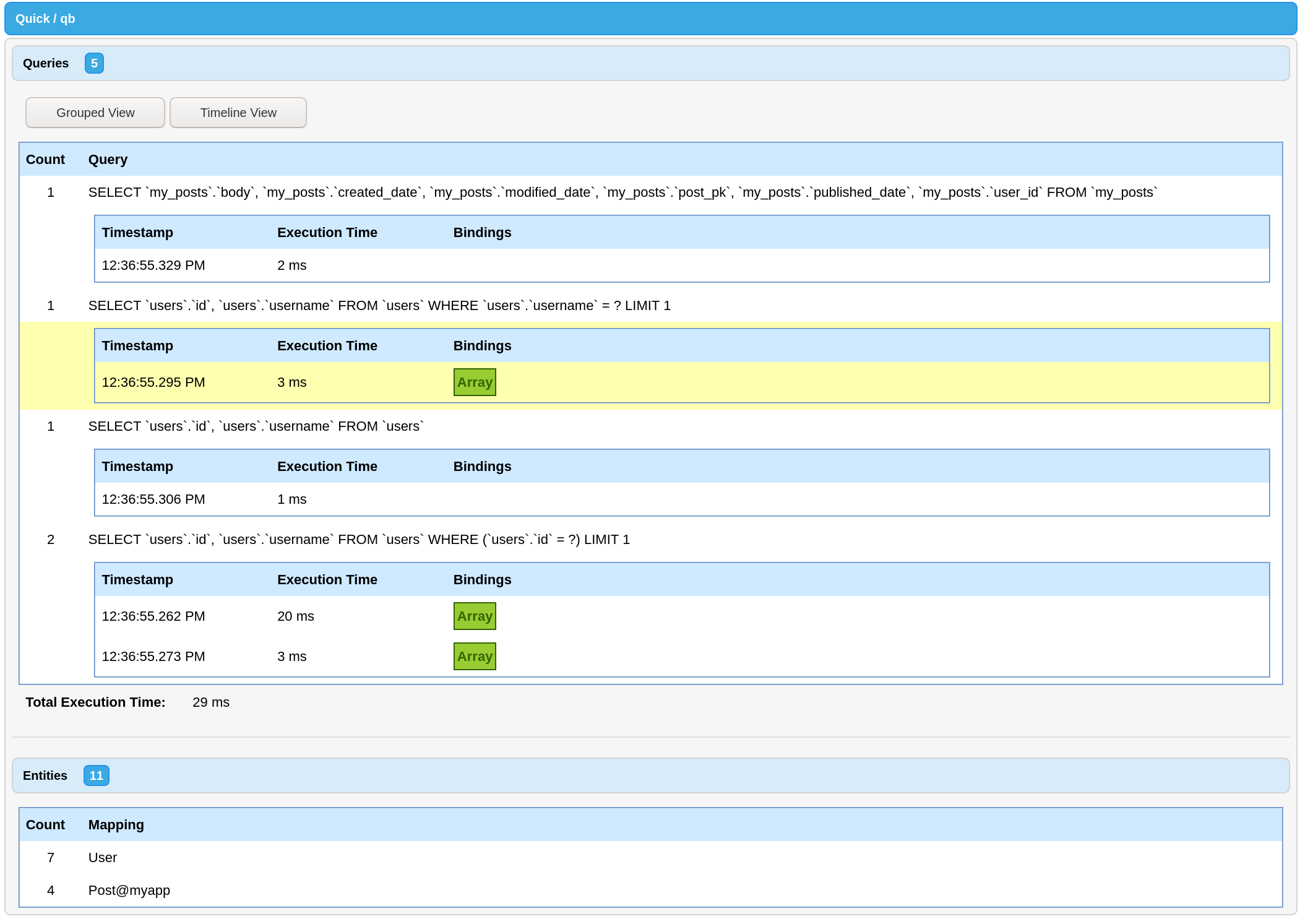
};
query.select( [ "fname AS firstName", "age" ] ).from( "users" );SELECT `fname` AS `firstName`, `age` FROM `users`query.select( "username" ).distinct().from( "users" );SELECT DISTINCT `username` FROM `users`query.addSelect( [ "fname AS firstName", "age" ] ).from( "users" );SELECT `fname` AS `firstName`, `age` FROM `users`query.selectRaw( "YEAR(birthdate) AS birth_year" ).from( "users" );SELECT YEAR(birthdate) AS birth_year FROM `users`query.subSelect( "last_login_date", function( q ) {
q.selectRaw( "MAX(created_date)" )
.from( "logins" )
.whereColumn( "users.id", "logins.user_id" );
} ) ).from( "users" );SELECT (
SELECT MAX(created_date)
FROM `logins`
WHERE `users`.`id` = `logins`.`user_id`
) AS `last_login_date`
FROM `usersquery.from( "users" )
.select( [ "fname AS firstName", "age" ] )
.clearSelect();SELECT * FROM `users`query.from( "users" )
.select( [ "fname AS firstName", "age" ] )
.reselect( "username" );SELECT `username` FROM `users`query.from( "users" )
.select( [ "fname AS firstName", "age" ] )
.reselectRaw( "YEAR(birthdate) AS birth_year" );SELECT YEAR(birthdate) AS birth_year FROM `users`query.from( "users" )
.orderBy( "email" );SELECT *
FROM `users`
ORDER BY `email` ASCquery.from( "users" )
.orderBy( "email" )
.orderBy( "username", "desc" );SELECT *
FROM `users`
ORDER BY
`email` ASC,
`username` DESCquery.from( "users" )
.orderBy( query.raw( "DATE(created_at)" ) );SELECT *
FROM `users`
ORDER BY DATE(created_at)query.from( "users" )
.orderBy( "email|asc,username", "desc" );SELECT *
FROM `users`
ORDER BY
`email` ASC,
`username` DESCquery.from( "users" )
.orderBy( [ "email|asc", "username" ], "desc" );SELECT *
FROM `users`
ORDER BY
`email` ASC,
`username` DESCquery.from( "users" )
.orderBy( [
{ "column": "email", "direction": "asc" },
"username"
], "desc" );SELECT *
FROM `users`
ORDER BY
`email` ASC,
`username` DESCquery.from( "users" )
.orderBy( function( q ) {
q.selectRaw( "MAX(created_date)" )
.from( "logins" )
.whereColumn( "users.id", "logins.user_id" );
} );SELECT *
FROM `users`
ORDER BY (
SELECT MAX(created_date)
FROM `logins`
WHERE `users`.`id` = `logins`.`user_id`
)query.from( "users" )
.orderByRaw( "CASE WHEN status = ? THEN 1 ELSE 0 END DESC", [ 1 ] );SELECT *
FROM `users`
ORDER BY CASE WHEN status = ? THEN 1 ELSE 0 END DESCquery.from( "users" )
.orderBy( "email" )
.clearOrders();SELECT *
FROM `users`query.from( "users" )
.orderBy( "email" )
.reorder( "username" );SELECT *
FROM `users`
ORDER BY `username` ASCschema.alter( "users", function( table ) {
table.addColumn( table.boolean( "is_active" ) );
} );ALTER TABLE `users` ADD `is_active` TINYINT(1) NOT NULLschema.alter( "registrars", function ( table ) {
table.addColumn(
table.raw( "HasDNSSecAPI bit NOT NULL CONSTRAINT DF_registrars_HasDNSSecAPI DEFAULT (0)" )
);
} );ALTER TABLE `registrars`
ADD HasDNSSecAPI bit NOT NULL
CONSTRAINT DF_registrars_HasDNSSecAPI DEFAULT (0)schema.alter( "users", function( table ) {
table.dropColumn( "username" );
} );ALTER TABLE `users` DROP COLUMN `username`schema.alter( "users", function( table ) {
table.modifyColumn( "name", table.string( "username" ) );
} );ALTER TABLE `users` CHANGE `name` `username` VARCHAR(255) NOT NULLschema.alter( "users", function( table ) {
table.renameColumn( "name", table.string( "username" ) );
} );ALTER TABLE `users` CHANGE `name` `username` VARCHAR(255) NOT NULLschema.alter( "users", function( table ) {
table.addConstraint( table.unique( "username" ) );
} );ALTER TABLE `users` ADD CONSTRAINT `unq_users_username` UNIQUE (`username`)schema.alter( "users", function( table ) {
table.dropConstraint( "unq_users_full_name" );
table.dropConstraint( table.unique( "username" ) );
} );ALTER TABLE `users` DROP INDEX `unq_users_full_name`
ALTER TABLE `users` DROP INDEX `unq_users_username`schema.alter( "users", function( table ) {
table.dropIndex( "idx_username" );
table.dropIndex( table.index( "username" ) );
} );ALTER TABLE `users` DROP INDEX `idx_username`
ALTER TABLE `users` DROP INDEX `idx_users_username`DROP INDEX [users].[idx_username]
DROP INDEX [users].[idx_users_username]schema.alter( "users", function( table ) {
table.renameConstraint( "unq_users_first_name_last_name", "unq_users_full_name" );
} );ALTER TABLE `users` RENAME INDEX `unq_users_first_name_last_name` TO `unq_users_full_name`schema.renameTable( "workers", "employees" );RENAME TABLE `workers` TO `employees`schema.rename( "workers", "employees" );RENAME TABLE `workers` TO `employees`schema.create( "products", function( table ) {
table.integer( "price" );
table.integer( "tax" ).storedAs( "price * 0.0675" );
} );CREATE TABLE `products` (
`price` INTEGER NOT NULL,
`tax` INTEGER GENERATED ALWAYS AS (price * 0.0675) STORED NOT NULL
)CREATE TABLE [products] (
[price] INTEGER NOT NULL,
[tax] AS (price * 0.0675) PERSISTED
)CREATE TABLE "products" (
"price" INTEGER NOT NULL,
"tax" INTEGER NOT NULL GENERATED ALWAYS AS (price * 0.0675) STORED
)CREATE TABLE "PRODUCTS" (
"PRICE" NUMBER(10, 0) NOT NULL,
"TAX" NUMBER(10, 0) GENERATED ALWAYS AS (price * 0.0675)
)schema.create( "products", function( table ) {
table.integer( "price" );
table.integer( "tax" ).virtualAs( "price * 0.0675" );
} );CREATE TABLE `products` (
`price` INTEGER NOT NULL,
`tax` INTEGER GENERATED ALWAYS AS (price * 0.0675) VIRTUAL NOT NULL
)CREATE TABLE [products] (
[price] INTEGER NOT NULL,
[tax] AS (price * 0.0675)
)CREATE TABLE "products" (
"price" INTEGER NOT NULL,
"tax" INTEGER GENERATED ALWAYS AS (price * 0.0675) STORED
)CREATE TABLE "PRODUCTS" (
"PRICE" NUMBER(10, 0) NOT NULL,
"TAX" NUMBER(10, 0) GENERATED ALWAYS AS (price * 0.0675) VIRTUAL
)schema.create( "users", function( table ) {
table.integer( "age" ).comment( "Do not lie about your age" );
} );CREATE TABLE `users` (
`age` INTEGER NOT NULL COMMENT `Do not lie about your age`
)schema.create( "users", function( table ) {
table.boolean( "is_active" ).default( 1 );
table.timestamp( "created_date" ).default( "NOW()" );
tablVIRTUAL NOT NULLe.string( "country" ).default( "'USA'" );
} );CREATE TABLE `users` (
`is_active` TINYINT(1) DEFAULT 1,
`created_date` TIMESTAMP DEFAULT NOW(),
`country` VARCHAR(255) DEFAULT 'USA'
)schema.create( "users", function( table ) {
table.timestamp( "last_logged_in" ).nullable()
} );CREATE TABLE `users` (
`last_logged_in` TIMESTAMP
)schema.create( "users", function( table ) {
table.uuid( "id" ).primaryKey();
} );CREATE TABLE `users` (
`id` CHAR(35) NOT NULL,
CONSTAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.create( "users", function( table ) {
table.unsignedInteger( "country_id" ).references( "id" ).onTable( "countries" ).onDelete( "cascade" );
} );CREATE TABLE `users` (
`country_id` INTEGER UNSIGNED NOT NULL,
CONSTRAINT `fk_users_country_id` FOREIGN KEY (`country_id`) REFERENCES `countries` (`id`) ON UPDATE NO ACTION ON DELETE CASCADE
)schema.create( "users", function( table ) {
table.integer( age" ).unsigned();
} );CREATE TABLE `users` (
`age` INTEGER UNSIGNED NOT NULL
)schema.create( "email", function( table ) {
table.string( email" ).unique();
} );CREATE TABLE `users` (
`email` VARCHAR(255) NOT NULL UNIQUE
)schema.create( "posts", function( table ) {
table.timestamp( "posted_date" ).withCurrent();
} );CREATE TABLE "posts" (
"posted_date" TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
)// manually
var schema = new qb.models.schema.SchemaBuilder(
grammar = new qb.models.grammars.MySQLGrammar(),
defaultOptions = { datasource: "my_datasource" }
defaultSchema = ""
);
// WireBox
var schema = wirebox.getInstance( "SchemaBuilder@qb" );schema.create( "users", function( table ) {
table.increments( "id" );
table.string( "email" );
table.string( "password" );
table.timestamp( "created_date" ).nullable();
table.timestamp( "modified_date" ).nullable();
} );CREATE TABLE `users` (
`id` INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,
`email` VARCHAR(255) NOT NULL,
`password` VARCHAR(255) NOT NULL,
`created_date` TIMESTAMP,
`modified_date` TIMESTAMP,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.alter( "users", function( table ) {
table.addConstraint( table.unique( "username" ) );
table.dropColumn( "last_logged_in" );
} );ALTER TABLE `users` ADD CONSTRAINT `unq_users_username` UNIQUE (`username`);
ALTER TABLE `users` DROP COLUMN `last_logged_in`;schema.drop( "user_logins" );DROP TABLE `user_logins`schema.rename( "posts", "blog_posts" );RENAME TABLE `posts` TO `blog_posts`schema.hasTable( "users" );SELECT 1
FROM `information_schema`.`tables`
WHERE `table_name` = 'users'schema.hasColumn( "users", "last_logged_in" );SELECT 1
FROM `information_schema`.`columns`
WHERE `table_name` = 'users'
AND `column_name` = 'last_logged_in'uuid split into and none.insertUsingJOIN statements in UPDATE statements. (This is not supported on Oracle.)min"array"moduleSettings = {
"qb": {
"shouldMaxRowsOverrideToAll": function( maxRows ) {
return false;
}
}
};query.from( "users" )
.where( "active", "=", 1 );SELECT *
FROM `users`
WHERE `active` = ?query.from( "users" )
.where( "last_logged_in", ">", query.raw( "NOW()" ) );SELECT *
FROM `users`
WHERE `last_logged_in` > NOW()query.from( "users" )
.where( "active", 1 );SELECT *
FROM `users`
WHERE `active` = ?query.from( "users" )
.where( function( q ) {
q.where( "active", 1 )
.where( "last_logged_in", ">", dateAdd( "ww", -1, now() ) )
} );SELECT *
FROM `users`
WHERE (
`active` = ?
AND
`last_logged_in` > ?
)query.from( "users" )
.where( "email", "foo" )
.orWhere( "id", "=", function( q ) {
q.select( q.raw( "MAX(id)" ) )
.from( "users" )
.where( "email", "bar" );
} );SELECT *
FROM `users`
WHERE `email` = ?
OR `id` = (
SELECT MAX(id)
FROM `users`
WHERE `email` = ?
)query.from( "users" )
.whereBetween( "id", 1, 2 );SELECT *
FROM `users`
WHERE `id` BETWEEN ? AND ?query.from( "users" )
.whereBetween(
"id",
function( q ) {
q.select( q.raw( "MIN(id)" ) )
.from( "users" )
.where( "email", "bar" );
},
builder.newQuery()
.select( builder.raw( "MAX(id)" ) )
.from( "users" )
.where( "email", "bar" )
);SELECT *
FROM `users`
WHERE `id` BETWEEN (
SELECT MIN(id)
FROM `users`
WHERE `email` = ?
)
AND (
SELECT MAX(id)
FROM `users`
WHERE `email` = ?
)query.from( "users" )
.whereColumn( "first_name", "=", "last_name" );SELECT *
FROM `users`
WHERE `first_name` = `last_name`query.from( "users" )
.whereColumn( "first_name", "last_name" );SELECT *
FROM `users`
WHERE `first_name` = `last_name`query.from( "users" )
.whereColumn( "first_name", query.raw( "LOWER(first_name)" ) );SELECT *
FROM `users`
WHERE `first_name` = LOWER(first_name)query.from( "orders" )
.whereExists( function( q ) {
q.select( q.raw( 1 ) )
.from( "products" )
.whereColumn( "products.id", "orders.id" );
} );SELECT *
FROM `orders`
WHERE EXISTS (
SELECT 1
FROM `products`
WHERE `products`.`id` = `orders`.`id`
)var existsQuery = query.newQuery()
.select( q.raw( 1 ) )
.from( "products" )
.whereColumn( "products.id", "orders.id" );
query.from( "orders" )
.whereExists( existsQuery );SELECT *
FROM `orders`
WHERE EXISTS (
SELECT 1
FROM `products`
WHERE `products`.`id` = `orders`.`id`
)query.from( "users" )
.whereLike( "username", "J%" );SELECT *
FROM `users`
WHERE `username` LIKE ?query.from( "users" )
.whereNotLike( "username", "J%" );SELECT *
FROM `users`
WHERE `username` NOT LIKE ?query.from( "orders" )
.whereIn( "id", [ 1, 4, 66 ] );SELECT *
FROM `orders`
WHERE `id` IN (?, ?, ?)query.from( "orders" )
.whereIn( "id", "1,4,66" );SELECT *
FROM `orders`
WHERE `id` IN (?, ?, ?)query.from( "orders" )
.whereIn( "id", [ 1, 4, { value = "66", cfsqltype = "CF_SQL_VARCHAR" } ] );SELECT *
FROM `orders`
WHERE `id` IN (?, ?, ?)query.from( "orders" )
.whereIn( "id", [ query.raw( "MAX(id)" ), 4, 66 ] );SELECT *
FROM `orders`
WHERE `id` IN (MAX(id), ?, ?)query.from( "users" )
.whereIn( "id", function( q ) {
q.select( "id" )
.from( "users" )
.where( "age", ">", 25 );
} );SELECT *
FROM `users`
WHERE IN (
SELECT `id`
FROM `users`
WHERE `age` > ?
)query.from( "users" )
.whereRaw(
"id = ? OR email = ? OR is_admin = 1",
[ 1, "foo" ]
);SELECT *
FROM `users`
WHERE id = ? OR email = ? OR is_admin = 1query.from( "users" )
.whereNull( "id" );SELECT *
FROM `users`
WHERE `id` IS NULLquery.from( "users" )
.where( "username", "like", "j%" )
.andWhere( function( q ) {
q.where( "isSubscribed", 1 )
.orWhere( "isOnFreeTrial", 1 );
} );SELECT *
FROM `users`
WHERE `username` LIKE ?
AND (
`isSubscribed` = ?
OR
`isOnFreeTrial` = ?
)query.from( "users" )
.whereUsername( "like", "j%" )
.whereActive( 1 );SELECT *
FROM `users`
WHERE `username` LIKE ?
AND `active` = ?query.from( "users" )
.join( "posts", "users.id", "=", "posts.author_id" );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`query.from( "users" )
.join( "posts", "users.id", "posts.author_id" );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`query.from( "users" )
.join( query.raw( "posts (nolock)" ), "users.id", "=", "posts.author_id" );SELECT *
FROM [users]
JOIN posts (nolock)
ON [users].[id] = [posts].[author_id]query.from( "users" )
.join( "posts", function( j ) {
j.on( "users.id", "=", "posts.author_id" );
j.on( "users.prefix", "=", "posts.prefix" );
} );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`
AND `users`.`prefix` = `posts`.`prefix`query.from( "users" )
.join( "posts", function( j ) {
j.on( "users.id", "=", "posts.author_id" );
j.whereNotNull( "posts.published_date" );
} );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`
AND `posts`.`published_date` IS NOT NULLquery.from( "users" )
.join( "posts", function( j ) {
j.on( function( j1 ) {
j1.on( "users.id", "posts.author_id" )
.orOn( "users.id", "posts.reviewer_id" );
} );
j.whereNotNull( "posts.published_date" );
} );SELECT *
FROM `users`
JOIN `posts`
ON (
`users`.`id` = `posts`.`author_id`
OR `users`.`id` = `posts`.`reviewer_id`
)
AND `posts`.`published_date` IS NOT NULLvar j = query.newJoin( "contacts" )
.on( "users.id", "posts.author_id" );
query.from( "users" ).join( j );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`query.from( "users" )
.joinWhere( "contacts", "contacts.balance", "<", 100 );SELECT *
FROM `users`
JOIN `contacts`
WHERE `contacts`.`balance` < ?query.from( "users" )
.joinRaw( "posts (nolock)", "users.id", "posts.author_id" );SELECT *
FROM [users]
JOIN posts (nolock)
ON [users].[id] = [posts].[author_id]var sub = query.newQuery()
.select( "id" )
.from( "contacts" )
.whereNotIn( "id", [ 1, 2, 3 ] );
query.from( "users as u" )
.joinSub( "c", sub, "u.id", "=", "c.id" );SELECT *
FROM `users` AS `u`
JOIN (
SELECT `id`
FROM `contacts`
WHERE `id` NOT IN (?, ?, ?)
) AS `c`
ON `u`.`id` = `c`.`id`query.from( "users as u" )
.joinSub( "c", function ( q ) {
q.select( "id" )
.from( "contacts" )
.whereNotIn( "id", [ 1, 2, 3 ] );
}, "u.id", "=", "c.id" );SELECT *
FROM `users` AS `u`
JOIN (
SELECT `id`
FROM `contacts`
WHERE `id` NOT IN (?, ?, ?)
) AS `c`
ON `u`.`id` = `c`.`id`query.from( "users as u" )
.joinSub( "c", function ( q ) {
q.select( "id" )
.from( "contacts" )
.whereNotIn( "id", [ 1, 2, 3 ] );
}, function( j ) {
j.on( "u.id", "c.id" );
j.on( "u.type", "c.type" );
} );SELECT *
FROM `users` AS `u`
JOIN (
SELECT `id`
FROM `contacts`
WHERE `id` NOT IN (?, ?, ?)
) AS `c`
ON `u`.`id` = `c`.`id`
AND `u`.`type` = `c`.`type`query.from( "posts" )
.leftJoin( "users", "users.id", "posts.author_id" );SELECT *
FROM `posts`
LEFT JOIN `users`
ON `users`.`id` = `posts`.`author_id`query.from( "posts" )
.leftJoinRaw( "users (nolock)", "users.id", "posts.author_id" );SELECT *
FROM [posts]
LEFT JOIN users (nolock)
ON [users].[id] = [posts].[author_id]var sub = query.newQuery()
.select( "id" )
.from( "contacts" )
.whereNotIn( "id", [ 1, 2, 3 ] );
query.from( "users as u" )
.leftJoinSub( "c", sub, "u.id", "=", "c.id" );SELECT *
FROM `users` AS `u`
LEFT JOIN (
SELECT `id`
FROM `contacts`
WHERE `id` NOT IN (?, ?, ?)
) AS `c`
ON `u`.`id` = `c`.`id`query.from( "users" )
.rightJoin( "posts", "users.id", "posts.author_id" );SELECT *
FROM `users`
RIGHT JOIN `posts`
ON `users`.`id` = `posts`.`author_id`query.from( "users" )
.rightJoinRaw( "posts (nolock)", "users.id", "posts.author_id" );SELECT *
FROM [users]
LEFT JOIN posts (nolock)
ON [users].[id] = [posts].[author_id]var sub = query.newQuery()
.select( "id" )
.from( "contacts" )
.whereNotIn( "id", [ 1, 2, 3 ] );
query.from( "users as u" )
.rightJoinSub( "c", sub, "u.id", "=", "c.id" );SELECT *
FROM `users` AS `u`
RIGHT JOIN (
SELECT `id`
FROM `contacts`
WHERE `id` NOT IN (?, ?, ?)
) AS `c`
ON `u`.`id` = `c`.`id`query.from( "users" ).crossJoin( "posts" );SELECT *
FROM `users`
CROSS JOIN `posts`query.from( "users" ).crossJoinRaw( "posts (nolock)" );SELECT *
FROM [users]
CROSS JOIN posts (nolock)var sub = query.newQuery()
.select( "id" )
.from( "contacts" )
.whereNotIn( "id", [ 1, 2, 3 ] );
query.from( "users as u" ).crossJoinSub( "c", sub );SELECT *
FROM `users` AS `u`
CROSS JOIN (
SELECT `id`
FROM `contacts`
WHERE `id` NOT IN (?, ?, ?)
)var j = query.newJoin( "contacts" )
.on( "users.id", "posts.author_id" );
query.from( "users" ).join( j );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`// This is still an inner join because
// the JoinClause is an inner join
var j = query.newJoin( "contacts", "inner" )
.on( "users.id", "posts.author_id" );
query.from( "users" ).leftJoin( j );-- This is still an inner join because
-- the JoinClause is an inner join
SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`var j = query.newJoin( "contacts" )
.on( "users.id", "posts.author_id" );
query.from( "users" ).join( j );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`var j = query.newJoin( "contacts" )
.on( "users.id", "posts.author_id" )
.orOn( "users.id", "posts.reviewer_id" );
query.from( "users" ).join( j );SELECT *
FROM `users`
JOIN `posts`
ON `users`.`id` = `posts`.`author_id`
OR `users`.`id` = `posts`.`reviewer_id`moduleSettings = {
"qb": {
"preventDuplicateJoins": true
}
};schema.create( "users", function( table ) {
table.bigIncrements( "id" );
} );CREATE TABLE `users` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.create( "users", function( table ) {
table.bigInteger( "salary" );
} );CREATE TABLE `users` (
`salary` BIGINT NOT NULL
)schema.create( "users", function( table ) {
table.bigInteger( "salary", 5 );
} );CREATE TABLE `users` (
`salary` BIGINT(5) NOT NULL
)schema.create( "users", function( table ) {
table.bit( "is_active" );
} );CREATE TABLE `users` (
`is_active` BIT(1) NOT NULL
)schema.create( "users", function( table ) {
table.bit( "is_active", 2 );
} );CREATE TABLE `users` (
`is_active` BIT(2) NOT NULL
)schema.create( "users", function( table ) {
table.boolean( "is_subscribed" );
} );CREATE TABLE `users` (
`is_subscribed` TINYINT(1) NOT NULL
)schema.create( "students", function( table ) {
table.char( "grade" );
} );CREATE TABLE `students` (
`grade` CHAR(1) NOT NULL
)schema.create( "users", function( table ) {
table.char( "tshirt_size", 4 );
} );CREATE TABLE `users` (
`tshirt_size` CHAR(4) NOT NULL
)schema.create( "users", function( table ) {
table.date( "birthday" );
} );CREATE TABLE `users` (
`birthday` DATE NOT NULL
)schema.create( "users", function( table ) {
table.datetime( "hire_date" );
} );CREATE TABLE `users` (
`hire_date` DATETIME NOT NULL
)schema.create( "posts", function( table ) {
table.datetimeTz( "posted_date" );
} );CREATE TABLE [posts] (
[posted_date] DATETIMEOFFSET NOT NULL
)schema.create( "weather", function( table ) {
table.decimal( "temperature" );
} );CREATE TABLE `weather` (
`temperature` DECIMAL(10,0) NOT NULL
)schema.create( "weather", function( table ) {
table.decimal( "temperature", 4 );
} );CREATE TABLE `weather` (
`temperature` DECIMAL(4,0) NOT NULL
)schema.create( "weather", function( table ) {
table.decimal( name = "temperature", precision = 2 );
} );CREATE TABLE `weather` (
`temperature` DECIMAL(10,2) NOT NULL
)schema.create( "users", function( table ) {
table.enum( "tshirt_size", [ "S", "M", "L", "XL", "XXL" ] );
} );CREATE TABLE `users` (
`tshirt_size` ENUM(`S`, `M`, `L`, `XL`, `XXL`) NOT NULL
)schema.create( "weather", function( table ) {
table.float( "temperature" );
} );CREATE TABLE `weather` (
`temperature` FLOAT(10,0) NOT NULL
)schema.create( "weather", function( table ) {
table.float( "temperature", 4 );
} );CREATE TABLE `weather` (
`temperature` FLOAT(4,0) NOT NULL
)schema.create( "weather", function( table ) {
table.float( name = "temperature", precision = 2 );
} );CREATE TABLE `weather` (
`temperature` FLOAT(10,2) NOT NULL
)schema.create( "users", function( table ) {
table.guid( "id" ).primaryKey();
} );CREATE TABLE `games` (
`id` uniqueidentifier NOT NULL,
CONSTRAINT `pk_games_id` PRIMARY KEY (`id`)
)CREATE TABLE `games` (
`id` VARCHAR(36) NOT NULL,
CONSTRAINT `pk_games_id` PRIMARY KEY (`id`)
)schema.create( "users", function( table ) {
table.increments( "id" );
} );CREATE TABLE `users` (
`id` INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.create( "games", function( table ) {
table.integer( "score" );
} );CREATE TABLE `games` (
`score` INTEGER NOT NULL
)schema.create( "games", function( table ) {
table.integer( "score", 3 );
} );CREATE TABLE `games` (
`score` INTEGER(3) NOT NULL
)schema.create( "users", function( table ) {
table.json( "options" ).nullable();
} );CREATE TABLE `users` (
`options` JSON
)schema.create( "users", function( table ) {
table.lineString( "positions" );
} );CREATE TABLE `users` (
`positions` LINESTRING NOT NULL
)schema.create( "posts", function( table ) {
table.longText( "body" );
} );CREATE TABLE `posts` (
`body` LONGTEXT NOT NULL
)schema.create( "users", function( table ) {
table.mediumIncrements( "id" );
} );CREATE TABLE `users` (
`id` MEDIUMINT UNSIGNED NOT NULL AUTO_INCREMENT,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.create( "games", function( table ) {
table.mediumInteger( "score" );
} );CREATE TABLE `games` (
`score` MEDIUMINT NOT NULL
)schema.create( "games", function( table ) {
table.mediumInteger( "score", 5 );
} );CREATE TABLE `games` (
`score` MEDIUMINT(5) NOT NULL
)schema.create( "posts", function( table ) {
table.mediumText( "body" );
} );CREATE TABLE `posts` (
`body` MEDIUMTEXT NOT NULL
)CREATE TABLE `posts` (
`body` VARCHAR(MAX) NOT NULL
)schema.create( "transactions", function( table ) {
table.money( "amount" );
} );CREATE TABLE `transactions` (
`amount` INTEGER NOT NULL
)CREATE TABLE [transactions] (
[amount] MONEY NOT NULL
)schema.create( "tags", function( table ) {
table.morphs( "taggable" );
} );CREATE TABLE `tags` (
`taggable_id` INTEGER UNSIGNED NOT NULL,
`taggable_type` VARCHAR(255) NOT NULL,
INDEX `taggable_index` (`taggable_id`, `taggable_type`)
)schema.create( "tags", function( table ) {
table.nullableMorphs( "taggable" );
} );CREATE TABLE `tags` (
`taggable_id` INTEGER UNSIGNED,
`taggable_type` VARCHAR(255),
INDEX `taggable_index` (`taggable_id`, `taggable_type`)
)schema.create( "posts", function( table ) {
table.nullableTimestamps();
} );CREATE TABLE `posts` (
`createdDate` TIMESTAMP,
`modifiedDate` TIMESTAMP
)schema.create( "users", function( table ) {
table.point( "position" );
} );CREATE TABLE `users` (
`position` POINT NOT NULL
)schema.create( "users", function( table ) {
table.polygon( "positions" );
} );CREATE TABLE `users` (
`positions` POLYGON NOT NULL
)schema.create( "users", function( table ) {
table.raw( "`profile_image` BLOB NOT NULL" );
} );CREATE TABLE `users` (
`profile_image` BLOB NOT NULL
)schema.create( "users", function( table ) {
table.smallIncrements( "id" );
} );CREATE TABLE `users` (
`id` SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.create( "games", function( table ) {
table.smallInteger( "score" );
} );CREATE TABLE `games` (
`score` SMALLINT NOT NULL
)schema.create( "games", function( table ) {
table.smallInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` SMALLINT(3) NOT NULL
)schema.create( "transactions", function( table ) {
table.smallMoney( "amount" );
} );CREATE TABLE `transactions` (
`amount` INTEGER NOT NULL
)CREATE TABLE [transactions] (
[amount] SMALLMONEY NOT NULL
)schema.create( "posts", function( table ) {
table.softDeletes();
} );CREATE TABLE `posts` (
`deletedDate` TIMESTAMP
)schema.create( "posts", function( table ) {
table.softDeletesTz();
} );CREATE TABLE [posts] (
[deletedDate] DATETIMEOFFSET
)schema.create( "users", function( table ) {
table.string( "username" );
} );CREATE TABLE `users` (
`username` VARCHAR(255) NOT NULL
)schema.create( "users", function( table ) {
table.string( "username", 50 );
} );CREATE TABLE `users` (
`username` VARCHAR(50) NOT NULL
)schema.create( "posts", function( table ) {
table.text( "body" );
} );CREATE TABLE `posts` (
`body` TEXT NOT NULL
)schema.create( "recurring_tasks", function( table ) {
table.time( "fire_time" );
} );CREATE TABLE "recurring_tasks" (
"fire_time" TIME NOT NULL
)schema.create( "recurring_tasks", function( table ) {
table.timeTz( "fire_time" );
} );CREATE TABLE "recurring_tasks" (
"fire_time" TIME WITH TIME ZONE NOT NULL
)schema.create( "users", function( table ) {
table.timestamp( "created_at" );
} );CREATE TABLE `users` (
`created_at` TIMESTAMP NOT NULL
)schema.create( "posts", function( table ) {
table.timestamps();
} );CREATE TABLE `posts` (
`createdDate` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`modifiedDate` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
)schema.create( "posts", function( table ) {
table.timestampTz( "posted_date" );
} );CREATE TABLE "posts" (
"posted_date" TIMESTAMP WITH TIME ZONE NOT NULL
)schema.create( "posts", function( table ) {
table.timestampsTz();
} );CREATE TABLE "posts" (
"createdDate" TIMESTAMP WITH TIME ZONE NOT NULL,
"modifiedDate" TIMESTAMP WITH TIME ZONE NOT NULL
)schema.create( "users", function( table ) {
table.tinyIncrements( "id" );
} );CREATE TABLE `users` (
`id` TINYINT UNSIGNED NOT NULL AUTO_INCREMENT,
CONSTRAINT `pk_users_id` PRIMARY KEY (`id`)
)schema.create( "games", function( table ) {
table.tinyInteger( "score" );
} );CREATE TABLE `games` (
`score` TINYINT NOT NULL
)schema.create( "games", function( table ) {
table.tinyInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` TINYINT(3) NOT NULL
)schema.create( "posts", function( table ) {
table.longText( "body" );
} );CREATE TABLE `posts` (
`body` LONGTEXT NOT NULL
)CREATE TABLE [posts] (
[body] NVARCHAR(MAX) NOT NULL
)schema.create( "posts", function( table ) {
table.unicodeMediumText( "body" );
} );CREATE TABLE `posts` (
`body` MEDIUMTEXT NOT NULL
)CREATE TABLE [posts] (
[body] NVARCHAR(MAX) NOT NULL
)schema.create( "users", function( table ) {
table.unicodeString( "username" );
} );CREATE TABLE `users` (
`username` VARCHAR(255) NOT NULL
)CREATE TABLE [users] (
[username] NVARCHAR(255) NOT NULL
)schema.create( "users", function( table ) {
table.unicodeString( "username", 50 );
} );CREATE TABLE `users` (
`username` VARCHAR(50) NOT NULL
)CREATE TABLE [users] (
[username] NVARCHAR(50) NOT NULL
)schema.create( "posts", function( table ) {
table.unicodeText( "body" );
} );CREATE TABLE `posts` (
`body` TEXT NOT NULL
)CREATE TABLE [posts] (
[body] NVARCHAR(MAX) NOT NULL
)schema.create( "games", function( table ) {
table.unsignedBigInteger( "score" );
} );CREATE TABLE `games` (
`score` BIGINT UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedBigInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` BIGINT(3) UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedInteger( "score" );
} );CREATE TABLE `games` (
`score` INTEGER UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` INTEGER(3) UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedMediumInteger( "score" );
} );CREATE TABLE `games` (
`score` MEDIUMINT UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedMediumInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` MEDIUMINT(3) UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedSmallInteger( "score" );
} );CREATE TABLE `games` (
`score` SMALLINT UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedSmallInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` SMALLINT(3) UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedTinyInteger( "score" );
} );CREATE TABLE `games` (
`score` TINYINT UNSIGNED NOT NULL
)schema.create( "games", function( table ) {
table.unsignedTinyInteger( "score", 3 );
} );CREATE TABLE `games` (
`score` TINYINT(3) UNSIGNED NOT NULL
)schema.create( "users", function( table ) {
table.uuid( "id" ).primaryKey();
} );CREATE TABLE `games` (
`id` VARCHAR(35) NOT NULL,
CONSTRAINT `pk_games_id` PRIMARY KEY (`id`)
)